如何为127kW高密度机柜降温?
来源:本站 发表时间: 2026年03月03日
在AI算力爆发式增长的当下,超大规模数据中心作为算力规模化部署的核心载体,其机柜算力密度正持续突破极限。传统风冷技术已难以满足高密AI算力的散热需求,逐渐退出该领域的主流散热舞台。本文将深入解析一份面向NVIDIAGB200NVL72系统的100MW超大规模AI数据中心参考蓝图,重点剖析其制冷架构设计。

制冷架构概览:CDU为核心的液冷方案
该100MW蓝图专为超大规模AI工作负载设计,其核心计算单元是NVIDIAGB200NVL72机架系统——每个机架容纳72块NVIDIAGPU和36颗NVIDIAGraceCPU,通过NVLink互联,额定功率高达127kW。
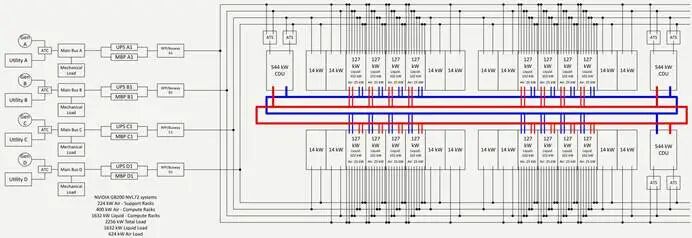
针对如此高的功率密度,该架构摒弃了传统风冷为主的散热方案,采用芯片直连液冷(D2C)为核心、风冷为辅助的混合制冷策略,结合温水液冷标准与模块化设计,构建了从机柜到pod、从散热末端到冷量分配的全链路制冷架构。每个机架都配备专用的液冷系统,通过模块化设计的CDU(CoolingDistributionUnit,冷却分配单元)来满足高密度AI系统的液体冷却热负荷。
同时,作为面向UL市场(美国保险商实验室简称,是全球权威的产品安全测试和认证机构)的TierIII容错等级数据中心,其制冷系统需满足并行维护、故障隔离的核心要求,且要适配pod级模块化的整体部署逻辑——40个模块化pod支撑100MW总IT负载,单pod32机柜(计算+网络)的IT负载达2256kW,其中液冷热负荷1632kW,风冷仅为624kW(辅助散热)。注:Pod为一组封闭冷(热)通道。
核心设计:三级架构+温水液冷,实现散热与能效的平衡
该制冷架构以“机柜级专属散热-pod级冷量分配-园区级自然冷却利用”为三级核心逻辑,全程遵循ASHRAEW32–W45温水液冷标准(供水温度32℃-45℃),核心目标是实现热负荷精准匹配、自然冷却最大化、制冷系统与算力/电力系统深度协同。

机柜级:芯片直连液冷为主,风冷辅助,127kW热负荷全覆盖
NVIDIAGB200NVL72计算柜采用液冷“102kW+风冷25kW”的精准散热方案。直连芯片液冷冷板采用定制化设计,与 NVIDIA GB200 NVL72 的 GPU、CPU 封装尺寸完全匹配,贴合紧密,热交换效率远高于传统风冷;机柜内的电源、网络设备等非核心部件则由风冷完成辅助散热。这种设计让散热精准匹配设备的发热特征,从末端杜绝了“过冷却”带来的能效损耗,同时为每台液冷机柜配备专属的遥测与控制网关,实时监测冷却液的温度、压力、流量,为后续的动态调节奠定基础。
pod级:3台CDU800模块化部署,支撑1632kW液冷热负荷
单pod配置3台CDU800冷却分配单元,单台CDU800的额定冷量为544kW,三台总容量1632kW,与单pod的液冷热负荷完全匹配,实现冷量的精准分配。
CDU800的设计是pod级制冷的最大亮点:采用双泵双路独立供电模式,每台泵配备单独的外部电源馈电,摒弃了传统单路供电CDU的单输入断路器风险。单台CDU800仅需1台泵运行,即可输出544kW的满额冷却容量,即使其中一台泵、控制系统或供电回路故障,另一台泵可无缝接替,制冷性能无任何衰减,实现了电力可用性与热冷却容量的解耦,无需额外配置N+1CDU冗余,既节省了设备成本,又提升了系统可靠性。
同时,pod级制冷采用A/B双路冗余的冷量分配路径,冷却管路部署在柜列级/机房层,确保在单一路径维护或故障时,另一路径可持续供冷,满足TierIII并行维护的核心要求。
园区级:ASHRAE温水液冷+自然冷却最大化,大幅降低PUE
整个制冷架构全程遵循ASHRAEW32–W45温水液冷标准,这是实现能效优化的核心关键。32℃-45℃的温水液冷大幅降低了冷却液的降温需求,使得数据中心在温带地区全年大部分时间可实现无冷水机运行,完全依靠自然冷却(冷却塔或干冷器)完成冷却液的温度调节,大幅减少机械制冷的能耗,这也与即将发布的新版GB50174对于PUE的要求契合。
关键技术亮点:容错、解耦、模块化,适配超大规模AI算力需求
TierIII容错设计:无单一故障点,支持并行维护
CDU800的双泵双电冗余,整个制冷架构的全链路均采用故障隔离设计:机柜级配备自动隔离阀门,一旦检测到泄漏,可毫秒级关闭该机柜的冷却液通路,不影响其他机柜;pod级的冷量分配采用双路冗余,单一路径故障可快速切换;园区级的自然冷却/机械制冷设备均采用N+1冗余,确保冷量制备的持续性。
同时,所有制冷设备均支持在线维护,CDU800的泵组、阀门等核心部件采用热插拔设计,可在设备正常运行的前提下完成更换,真正实现“维护不关机,故障不影响”。
电力与制冷解耦:告别“电力故障=制冷衰减”
该架构CDU800的一泵一电、独立供电设计,彻底实现了电力可用性与热冷却容量的解耦:
pod级模块化设计:适配分阶段建设,支持算力阶梯式扩容
100MW超大规模数据中心的建设遵循分阶段、阶梯式的算力扩容逻辑,其制冷系统的pod级模块化设计完美适配这一需求。同时,pod内的制冷管路与CDU部署预留了充足的扩容空间,若后续算力密度进一步提升(如升级至NVIDIAGB300NVL72),可在单pod内直接增加第四台CDU800,制冷容量从1632kW提升至2176kW,无需改造现有管路与控制逻辑,实现制冷系统与下一代算力集群的无缝兼容。
结语
在AI算力持续爆发的未来,超大规模数据中心的制冷系统将不再是简单的“散热工具”,而是与算力、电力深度融合的核心子系统,其设计的科学性、可靠性、可扩展性,将直接决定数据中心的算力输出、运营成本与长期发展。这套制冷架构的落地,为行业提供了可复制、可推广的标杆方案,也为高密AI数据中心的制冷技术发展指明了清晰方向。